


Už kdysi dávno v článku o "Analogové logice" jsem zmiňoval, že robot, který se rozhoduje na základě pouze těch posledních měření dat z čidel má zaděláno na problémy způsobené šumem v těchto datech. Už tenkrát jsem doporučoval průměrovat, průměrovat, průměrovat.
Aritmetický průměr je dětsky jednoduchá matematická operace, která se učí snad někdy na prvnim stupni takže by se zdálo, že ani není o čem psát. Protože, jako vždycky, se "ďábel skrývá v detailech" je od průměru ve 4. třídě k průmměru ve firmwaru robota na Robotickém dni přece jenom nějaká ta cesta.
Zásadní problém průměrování v robotech je, že nemáme nikdy k dispozici všechna data. průměrování v robotech totiž nefunguje jako na cvičení z matematiky - kdy dostaneme tabulku se všemi daty a počítáme jak se nám zlíbí. V robotech na jedné straně čidla neustále chrlí nová a nová data a na druhé straně ať máme paměti jakkoliv mnoho - jednou prostě paměť dojde a budeme muset stará data zahazovat. Algoritmus pro půměr v robotovi tudíž musí být tzv. "proudový" od anglického Stream - proud. Tedy napsaný tak, že s každým měřením přijde jedna hodnota na začátek "pásu" a na konci pásu vypadne jeden výsledek.
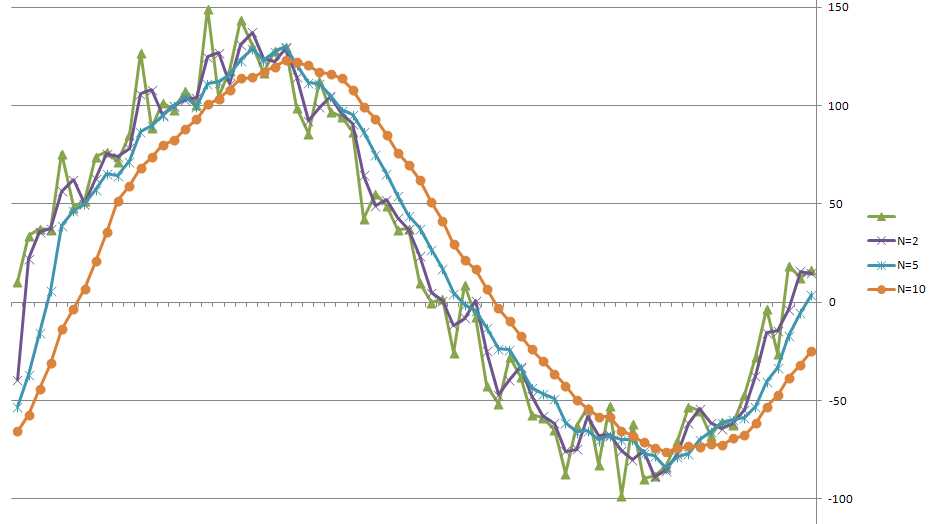
V případě průměrů těmto nárokům nejlélpe vyhovují tzv - klouzavé průměry. O co se jedná je vidět z obrázku - původní "zašumělá" data jsou zelená, a ostatní křivky jsou klouzavé průměry pro 2, 5 a 10 sousedních hodnot. Takže klouzavý průměr pro 5 hodnot se spočte tak, že (až se nám algoritmus ustálí) - třeba hodnotu č. 100 spočteme tak, že spolu sečteme hodnoty 100, 99 , 98 , 97 , 96 a vydělíme 5. Jednoduché, ale zase to zavání potřebou ukládat si do tabulky všechny naměřené hodnoty. To ve skutečnosti není potřeba, což si ukážema na nejnaivněji napsaném algoritmu pro "proudový" klouzavý průměr jaký lze napsat - budeme počítat klouzavý průměr pro 3 sousední hodnoty X je vstup, Y je výstup.
V pseudokódu by to bylo nějak takto
While ( !End ) {
A = B
B = C
C = X
Y = (A+B+C) / 3
}
Myslím, že je to jasné, - původní hodnoty pomocných proměnných A, B, C jsou vlastně poslední 3 měření, které se na začátku každého cyklu posouvají tak, že hodnota A se zahodí do ní uloží hodnota B, do té se uloží hodnota C do prázdného C se uloží poslední měření a spočte se průměr.
Pro 5 a více proměnných je tento algoritmus hrozivě neefektivní proto se často používá pro minulé hodnoty tzv "kruhový buffer" pole hodnot, s ukazatelem na poslední hodnotu. představme si třeba buffer o velikosti 10 a počítáme klouzavý průměr posledních 10 hodnot.
i=1
WHILE ( !END ) {
POSLEDNI = BUFFER [i]
SUMA = SUMA - POSLEDNI + X
Y = SUMA / 10
BUFFER [i] = X
i = i + 1
IF i > 10 THEN i = 1
}
Veškeré inicializace proměnných jsem samozřejmě vynechal. Vtip je v tom, že algoritmus už vůbec nepřipomíná sčítání sousedních hodnot. Představte si že proměnná POSLEDNI obsahuje hodnotu X z doby před 10 měřeními a proměnná SUMA obsahuje součet všech posledních 10 měření - takže pokud uděláme operaci SUMA = SUMA - POSLEDNI (odečteme 10 měření starou informaci) a když pak uděláme SUMA = SUMA + X tak přičteme nejnovější měření a tím se nám součet obsažený v proměnné SUMA o 1 měření "posune" vpřed.
Pak staré X uložíme do BUFFERU a hodnotu indexu i zvětšíme o 1 aby ukazovala na novou hodnotu. Pokud i je větší než velikost bufferu musíme i vrátit zase na začátek.
Samozřejmě že bychom mohli celý průměr počítat i naivně z hodnoty proměnné BUFFER jako
Y = ( BUFFER [1] + BUFFER [2] + .... BUFFER [10] ) / 10 ale to by bylo skoro stejně neefektivní jako posouvání hodnot ve stylu A=B, B=C, C=D atd ...
Pokud budete tento algoritmus programovat v Assembleru (nebo i v C) je výhodné používat buffer velikosti mocnin 2 - 2, 4, 8, 16 hodnot. pak jetaky dobré prvky bufferu očíslovat od 0 třeba do 7, protože pak můžete poslední dva řádky
i = i + 1
IF i > 7 THEN i = 0
Napsat jako
inc R16
andi R16, 7
neboli
i = ( i+1 ) & 7
neboli pro 16 hodnot
i = ( i+1 ) & 15
Poslední poznámka na závěr - s rostoucím počtem půměrovaných hodnot - klesá šum v datech - toho jste si jistě všimli na grafu. Je však nutno výslovně poznamenat, že s tím zároveň roste zpoždění, které do změn v datech průměr zanese. Nikdy jsem to příliš matematicky nestudoval ale zpoždení odpovídá přibližně polovně průměrovaných hodnot - tedy pokud průměrujeme 10 sousedních hodnot - dostaneme výsledky, které se oproti původním datům opožďují o 5 měření - pokud počítáte předem známé hodnoty z tabulky tak je vám to jedno, ale u robota nikdy "nevidíte do budoucnosti" - nezískáte budoucí měření - takže vám nezbyde než s touto neodstranitelnou vlastností klouzavého průměru počítat ...
Zbývá už jenom rada paní Kubáčové pro novomanželky - že miláček prdí před vámi už dlouho - to je známkou jeho důvěry ve vás, ale pokud vy začnete po svatbě prdět před ním - možná si bude mylně myslet, že se z vás stala novomanželka - čuně - takže mu ten systém vzájemné důvěry raději před prvním prdem vysvětlete...
Klouzavý průměr je nejjednodušší dolní propustí - FIR filtrem. Sice ne moc dobrým, ale zato výpočetně neskutečně nenáročným.
http://ptolemy.eecs.berkeley.edu/eecs20/week12/freqResponseRA.html