Jestli vás zaujala zkratka CVSDM tak to znamená Continuously variable slope delta modulation. A jestli si myslíte, že jsem se zbláznil a opustil vidlácký způsob konstrukce a programování robotů - tak se velice pletete.
Nebudu začínat ultrazvukem, ale představte si, že byste chtěli to nejjednodušší, co si u robotů představuje každé 2 leté děcko - aby robot vydával nějaké "bojové pokřiky"
Takže trošku počítejme - představte si že budete chtít do robota naprogramovat 1 sekundu toho nejubožejšího zvuku. Takže berme, že vzorkovací frekvence bude 8KHz (pro rozsah alespoň do 4 KHz řečového pásma) a hloubka vzorkování bude 8 bitů. To máme 8 kilobyte / sec - při kvalitě zvuku, který se "vyrovná" nejubožejším hračkám od Vietnamce.
Takže vás okamžtě napadne, že je potřebná nějaká datová komprese. Začnete studovat běžné učebnicové algoritmy a zjistíte, že žádný není pro zvuk příliš vhodný. Co je vhodné je varianta FFT = DCT = JPEG = MP3 komprese, ale to je na naše matematické schopnosti i na ubohý výkon našeho procesoru zase příliš.
Takže první věc, která vás napadne - nebudu ukládat celý vzorek, ale jenom rozdíl oproti minulému vzorku - BINGO - vzhledem k tomu, že zvuky jsou většinou hladké sinusovky, bude nejčastější rodíl téměř 0, takže nemusíte ukládat celých 8 bitů rozdílu, protože (třeba) horní 4 bity jsou skoro vždycky 0, ale ukládáte jenom spodní 4 bity. Máte zvuk jenom o něco málo ubožejší než předtím, a přitom polovinu dat. Tak tomuhle se říká DELTA MODULATION.
Delta modulace má dvě drobné chybky
1. Komprese v poměru 1:2 není nic moc
2. U prudkých výkyvů zvuku se často vyskytuje "podtečení delta" - tedy rozdíl vzorků je více než vaše maximální hodnota delta.
Proto můžeme použít "expanzi delta" ve smyslu následující tabulky
| Vyslaný kód | Hodnota delta |
| -3 | -64 |
| -2 | -8 |
| -1 | -1 |
| 0 | 0 |
| 1 | 1 |
| 2 | 8 |
| 3 | 64 |
Takže do databáze si uložíme 3bitové signed hodnoty a delta vybíráme z tabulky.
Postup jak se "surová data" třeba z WAW souboru kódují do podoby delta hodnot se nazývá Error Diffusion. Tedy při výpočtu odeslání "expandovaného delta" vznikne určitá chyba, která se přičte k hodnotě minulého vzorku aby se vzala do úvahy při výpočtu dalšího vzorku a nekumulovala se.
Příklad v Pseudokódu.
TRUE_ DELTA = CURRENT_X - LAST_X
SEND_DELTA = compress_delta (TRUE_DELTA)
ERROR_DELTA = TRUE_DELTA - expand_delta ( SEND_DELTA )
LAST_X = LAST_X + ERROR_DELTA
Jak jste jistě pochopili tak procedura COMPRESS_DELTA vezme skutečnou hodnotu delta a snaží se najít, která hodnota z pravého sloupce tabulky (tedy -64, -8, -1, 0, 1, 8, 64) je hodnotě delta nejbližší a podle toho vrací hodnotu -3 až +3.
Stejně tak je myslím jasné, že procedura EXPAND_DELTA bere hodnoty -3 až +3 a vrací -64, -8, -1, 0, 1, 8, 64.
Jasné ?
Stále máme ubohý zvuk, kompresi 3:8 a algoritmus jako hrom. Aby to bylo ještě horší když začnete studovat jaké hodnoty delta jsou vhodné zjistíte, že kolem toho je literatury jako hrom, protože to je oblíbené téma akadademiků. Nicméně od 70. let existuje metoda, která zajistí kompresi akustického signálu v poměru 1:8 tedy jeden vzorek kóduje se jedním bitem, nic se nemusí nastavovat a algoritmus si delta nastaví sám. Jistě tušíte, že to je to záhadné CVSDM.

Takže ukázka v pseudokódu:
ACCUMULATOR = 0
DELTA = 1
FOR I=0 TO SAMPLE_COUNT
IF SAMPLE > ACCUMULATOR THEN
BEGIN
send (1)
ACCUMULATOR = ACCUMULATOR + DELTA
END
ELSE
BEGIN
send (0)
ACCUMULATOR = ACCUMULATOR - DELTA
END
IF (last_3_send_bits = 0b111) or (last_3_send_bits = 0b000) THEN DELTA = DELTA * 2
ELSE DELTA = ( DELTA +1 ) div 2
ACCUMULATOR = ( 120 * ACCUMULATOR + 64 ) >> 7
NEXT I
Jasné ?
Předpokládám že ne zcela takže se to pokusím ještě popsat slovy. Hodnota ACCUMULATOR - de facto nese součet všech hodnot DELTA, které už byly odeslány. Nový vzorek se porovoná s hodnotou ACCUMULATORU a podle toho se pošle 1 - když je vzorek větší , nebo 0 když je menší a hodnota DELTA se podle toho k akumulátoru přičte / odečte.
Pak následuje záhadná část s úpravami hodnot delta. Pokud poslední 3 vzorky byly všechy menší nebo všechny větší než AKUMULATOR (to znamená že se odeslaly 3 x 1 nebo 3 x 0 za sebou)- znamená to, že hodnota DELTA je příliš malá - proto se zdvojnásobí, pokud nenastala ani jedna z těchno variant hodnota delta se zmenší na polovinu, ale ne na nulu, proto tam je to (DELTA +1) / 2.
Předposlední řádek je naprosto záhadná manipulace s hodnotou AKUMULÁTORU - jedná se o to, že pokud tento algoritmus použijeme pro přenos dat z jednoho místa do jiného a dojde k chybě přenosu - hodnota akumulátoru by se už nikdy nesrovnala - tento algoritmus se nazývá LEAKY ACCUMULATOR (prosakující akumulátor). Tedy hodnota akumulátoru se vlastně exponenciálně půměruje k nule aby se chyba přenosu postupně "vstřebala".
Dekódování je zrcadlovým obrazem kódování včetně leaky accumulatoru. Tedy udržujete hodnotu DELTA a přičítáte / odečítáte ji od hodnoty ACCUMULATORu a hodnota ACCUMULATORU je vlastně výstup celého kódování.
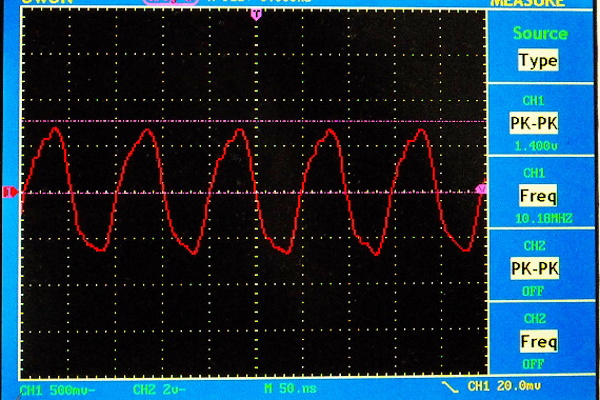
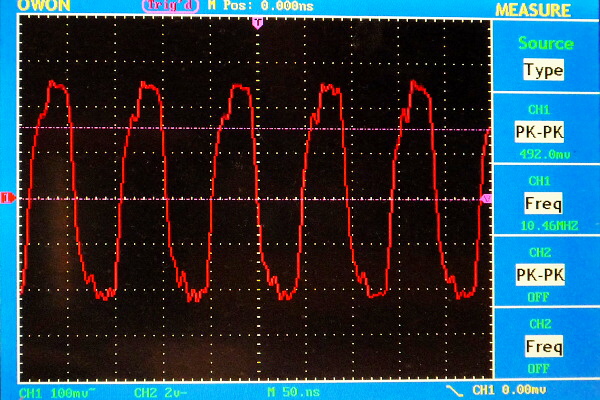
Jak vypadá originální a dekódovaný signál vidíte na obrázku - ty ostré "spajky" v dekódovaném signálu jsou situace kdy hodnota DELTA vzrostla až příliš - pokud vám vadí stačí prohnat výstup tím nejjednodušším exponenciláním průměrem. Zásadní výhoda CVSDM je v tom, že klidně můžete algoritmus beze změny použít i pro 16 bitové hodnoty - pozor na přetečení pracovních proměnných zejména při výpočtu LEAKY ACCUMULATORU. Hodnota DELTA se automaticky přizpůsobí. Navíc komprese 1:8 je dostatečná na to abyste si mohli dovolit samplovací frekvenci 16kHz a to je v signálu slyšet jako výrazné zlepšení zvuku.
Takže nakonec jsme došli k paradoxu ztrátových kompresí - ztrátově komprimovaný signál je někdy lepší než nekomprimovaný - alias na velikém vysoce komprimovaném JPEGu vidíme více než na maličkém GIFu.
Zbývá už jenom tradiční rada pro brunety - nepadnou vám ohnivě červené kozačky, které jsou v obchodě poslední - nic si z toho nedělejte - ve vedlejším regálu jsou černé důchodky a je jich tam spousta....