Roboti a Matematika
25. února 2016 v 5:07 | Petr
Přestože jsem prohlašoval, že s
robotickými a elektronickými články je konec, mám tady "
jeden takový projekt" při jehož zpracovávání jsem si vzpoměl na to, že jsme sice probírali "
oscilující" rozhodování jestli A = B nebo A > B, ale neprobrali jsme to nejjednodušší - jak přiměřeně "
bezpečně" alias "
blbuvzdorně" alias "
robustně" programovat jednoduché dvoustavové rozhodování - tedy máte teplotu a rozhodujete zda je "
horko" nebo "
zima" - máte světelnou intenzitu a rozhodujete zda je "
světlo" nebo "
tma" neboli máte analogový - numerický - signál z čidla a vy musíte dynamicky rozhodnout zda je to "
málo" nebo "
hodně".
Při té příležitosti bych si dovolil upozornint, že už kdysi dávno jsem prohlašoval, že čidlo, které produkuje jenom informaci ANO nebo NE - je nebezpečné a nemělo by se v robotech používat. A taky jsem kdysi prohlašoval, že veškerá čidla, která jsem kdy postavil dávala dokonce až DVĚ výstupní hoddnoty
- Samotnou "intenzitu signálu" ( ne ANO / NE ) ale v analogové škále
- Analogovou informaci o "kvalitě" tedy jak mnoho je si dané čidlo touto hodnotou jisto.
Takže si modelově ptředstavme tu nejjednodušší situaci - robot má měřič intenzity světla a má určit zda je "na slunku" nebo "ve stínu". Předpokládejme, že měřič má jednoduchý AD výstup, kde 0 je "absolutní tma" a 255 je "absolutní světlo". Taky si představme, že vůbec netušíme jakou hodnotu má stav "trochu šero" nebo "docela jasno" a přesto musíme nějak rozhodnout. Ba dokonce si představme, že hodnota "středně šero" nemusí být 128 - jak bychom naivně očekávali.
Víte co potom ? Opět částečně naivní postup je získat nějakou "rozhodovací mez" tedy třeba "pod 60 je to ve stínu", ale jak se k takové mezi dopracovat ? Dosti často se používá "startovní kalibrace" tedy změří se hodnota "než se vyjede" a od ní se pak odvodí rozhodovací limit. Někdy to funguje, ale představte si robota, který startuje a netuší jestli přitom stojí ve stínu, nebo na slunku. A potom některá čidla, aby zvládla třena venkovní světelné intenzity, mohou mít velice úzké rozmezí jako 63 je světlo a 58 je už tma ?
Předpokládám, že jste právě propadli nihilismu a odpovědí na mé otázky je prohledat "
Aliexpress" s příslušným
čtyřdírkovým modulem pro "
Arduííno" a pokud Číňani nic nevymysleli ( neukradli chytřejším ), máte tendenci předvést, že nejste chytřejší než Číňani - a na všecno se vykašlat ?
Nicméně to by nebyl tento blog, aby nějaké "vidlácké" ba dokonce "assemblerové" východisko nebylo. Berte tedy tento článek jako informaci, jak v mých robotech probíhá ( probíhalo ) jednoduché rozhodování typu SVĚTLO / TMA nebo prostě ANO / NE.
Celé kouzlo je v tom, že není jedna rozhodovací mez, ale DVĚ, který říkejme INTENZITA_SVĚTLA a INTENZITA_TMY. Pokud tedy předpokládáme vstup v hodnotách 0-255 je dobré obě intenzity na začátek nastavit na střední hodnotu 127.
Pak přijde nějaká hodnota z AD převodníku a pro rozhodování obecně platí
- Pokud NOVÁ_HODNOTA <= INTENZITA_TMY pak je výsledek TMA
- Pokud NOVÁ_HODNOTA >= INTENZITA_SVĚTLA pak je výsledek SVĚTLO
- Pokud je výsledek uprostřed mezi oběma "intezitami" - rozhodne se podle toho zda je NOVÁ HODNOTA blíže k hodnotě INTENZITY_SVĚTLA nebo k hodnotě INTEZITY_TMY
Mimochodem "numerická vzdálenost" na jednorozměrné číselné ose se počítá jako ABS ( NOVÁ_HODNOTA - INTENZITA_SVĚTLA ) případně jako ABS ( NOVÁ_HODNOTA - INTENZITA_TMY ). Takto složitě to však dělat nemusíme, porotože vyloučením varianty 1 a 2 víme. že NOVÁ_HODNOTA je uprostřed tedy naše zjednodušená podmínka bude
IF ( NOVÁ_HODNOTA - INTENZITA_TMY ) > ( INTENZITA_SVĚTLA - NOVÁ_HODNOTA ) THEN světlo ELSE tma
Co dělat v případě, že NOVÁ_HODNOTA je naprosto přesně uprostřed - nevím, ale v reále to za mně vyždy vyřešily nestability hodnot čidel, které způsobily, že výsledek se vždy nakonec "někam skulil".
Doposud se to zdá být jenom příliš složité řešení prajednoduché věci, ale teď přijde "
genialita Cimrmanovy myšlenky" - poté co jsme rozhodli zdali výsledek je SVĚTLO nebo TMA - vezmeme příslušný limit a jeho hodnotu "
updatujeme" nějakým třeba - dosti dlouhým
exponenciálním klouzavým průmerem.
Příklad - vyšla nám "tma" tak provedeme následující výpočet
INTEZITA_TMY = ( 7 * INTENZITA_TMY + HODNOTA ) >> 3
neboli bez assemblerovských bitových posuvů
INTEZITA_TMY = ( 7 * INTENZITA_TMY + HODNOTA ) / 8.
totéž s INTENZITOU_SVĚTLA, pokud je výsledek "světlo".
Matematikům mezi vámi, což jsou ostatně všichni - je to jasné. Kouzlo je totiž v tom, že po čase se INTEZITA_SVĚTLA dostane na typické hodnoty pro výsledek SVĚTLO a INTENZITA_TMY se dostane na hodnoty typické pro výsledek TMA.
To stále vypadá jako zbytečná kravina, ale není. Používání dvou limitů tímto způsobem má v sobě to kouzlo, že rozdíl mezi nimi nám dává potřebnou informaci o "kvalitě" neboli "blbuvzdornosti" rozhodování. Takže pokud po nějaké době jízdy je INTENZITA_TMY = 30 a INTENZITA SVĚTLA = 210 - je jasné, že čidlo je kvalitní a robot je si svými rozhodnutími perfektně jistý.
Pokud naopak i po nějaké době jízdy platí že INTENZITA_TMY ( téměř ) = INTENZITA SVĚTLA je jasné, že čidlo i jeho závěry nestojí za nic. Ba dokonce, pokud budeme úplní matematici - můžeme si krom "průměrných intenzit" počítat i jejich směrodatné odchylky a podle nich určit s jakou "statistickou významností" se obě intenzity liší a tudíž určit jestli "nejistota rozhodnutí" je 20, 10, 5, 1, nebo ještě méně procent. To je složitost, kterou sice umím, ale nikdy jsem ji v robotech nepoužíval, tudíž bych ji nechal na někdy jindy.
Detailisti mezi čtenáři jistě namítnou, že ani tento způsob není chráněn před špatnými rozhodnutími, hlavně na samém začátku. Ano je to pravda - tento algoritmus má potenciál rozhodovat stejně špatně jako prosté porovnání proti jednomu limitu. Na druhé straně chyba rozhodnutí v tomto algorimtu není "překvapivý zásah nepříznivého osudu" a dá se dopředu odhadnout, pokud se oba limity liší jenom málo. Což mimochodem vzhledem k nastavení obou "doprostřed škály" - je pravda i na začátku, při startu robota.
Jasné ?
7. ledna 2016 v 5:59 | Petr
Pojem zákeřnost v počítačových algoritmech by si zasluhoval vlastní definici, nebo dokonce vlastní seriál. Osobně jsem udělal se "zákeřností" tolik zkušeností, že bydlet v Praze už je ze mě profesor "průserů" na některé "počítače řešící" fakultě.
Místo složitých definic posloužím příkladem. V dřevních dobách nebyly "hardwarově akcelerované" 2D i 3D grafické knihovny - pokud jste chtěli mít lepší úsečku než kreslil driver SVGA.DRV z Turbo Pascalu - museli jste si ji naprogamovat sami.
Jedna z mých assemblerových - ďábělsky rychlých - avšak neúspěšných - procedur pro kreslení úsečky využívala algoritmu zvaného "midpoint subdivision".
procedure LINE ( X1, Y1, X2, Y2 );
begin
IF (X1=X2) AND (Y1=Y2) THEN EXIT;
X_CENTER = ( X1 + X2 ) DIV 2;
Y_CENTER = ( Y1 + YZ ) DIV 2;
PutPixel ( X_CENTER, Y_CENTER);
LINE ( X1, Y1, X_CENTER, Y_CENTER );
LINE ( X_CENTER, Y_CENTER, X2, Y2 );
end;
Takže pro Pascalem nevládoucí - je to takto : Máte úsečku odcamcaď pocamcaď - spočtete její střed a tam uděláte tečku a pak voláte stejný algoritmus pro levý a pravý úsek, které udělají další a další tečky až "postupným půlením" úsečky namalujete všechny body.
OK to vypadá docela ideálně až na dvě drobné vady - buď počítáte "střed" bez zaokroulení - tedy X_CENTER = ( X1 + X2 ) DIV 2; a potom se pro určité kombinace souřadnic algoritmus "kousne" protože nikdy nenastane stav (X1=X2) AND (Y1=Y2) nebo můžete počítat se zaokrouhlením - ve stylu : X_CENTER = ( X1 + X2 + 1 ) DIV 2; ale potom dostanete - "hnus fialový namalovaný" ve stylu úsečky, kterou vidíte nahoře - vidíte tam ty nepravidelnosti ?
Jediná šance je použít "subpixelovou přesnost" - tedy pracovat třeba s 8 násbokem hodnot souřadnic a před procedurou PutPixel - je obě vydělit, ale tím je veškeré "kouzlo" tohoto algoritmu, který je v assembleru opravdu ďábelsky rychlý - ztraceno.
Tedy jasné co to je "zákeřnost" ? Tohle ovšem byla zákeřnost celočíselného algoritmu - u reálných čísel to však není o nic lepší. Říká se například, že účetnictví se nedá dělat v reálných číslech, protože se dostáváme do problémů, že potřebujeme od 3,57835928 miliard odečíst pět korun - kolik nám zbyde ? Díky implicitnímu zaokrouhlování mantisy zase 3,57835928 miliard - je to "oslíčku otřes se" nebo je to chyba výpočtu a tím pádem průser ?
Proto se pro účetnictví používají celá čísla a počítá se na jden halíř - ovšem "jak kdy" například banky počítají úroky z vkladů ( které musí vyplatit ) s oblibou po měsících a zaokrouhlují je dolů. Zatímco úroky z hypoték ( které si berou ) počítají po dnech ( kdyby to bylo možné počítali by to po pikosekundách ) a zaokrouhlují nahoru - protože "tím se více vydělá". Vůbec bych se nedivil kdyby ve velkých bankách bylo celé oddělení "výpočetní ne-přesnosti" které by se zabývalo otázkou jak dělat "nežalovatelné numerické chyby ve prospěch firmy".
OK mají roboti něco společného s bankou ? Okamžitě mě napadá jedna věc - váš robot ujel po celdenním "
drandění" enkodérů 3,57835928 miliónů milimetrů a dostane příkaz - jeď ještě pět milimetrů a kolik bude "
konečná vzdálenost" opět 3,57835928 miliónů milimetrů ? Je to "
Zenonův paradox" nebo průser ve výpočtu ?
Takže je jasné, že na počítání čehokoliv "na kusy" potřebujeme celá čísla - což je zdánlívě přirozené, ale když vezmeme ty reálnými čísly počítané JPEGy - není to úplně intuitivní. Až budete přemýšlet jaký numerický formát použít - je třeba udělat tu složitou úvahu zdali je nutná "absolutní chyba" o jedničku - což znamená, že musíte používat celá čísla. To jsou úlohy typu přidej halíř k miliardě, nebo jestli je lepší použít relativní chybu typu "machine epsilon" - což vede k použití reálných čísel.
Pak je potřeba probrat ještě jednu věc - u reálných čísel a zejména u robotů ABSOLUTNĚ ZAKAZUJU používat konstrukce IF A=B THEN.... To je poukázka na zbláznění robota a přejetí maminy s kočárkem, nebo projetí zdí, nebo jiný průser. Tušítě proč ?
Kouzlo je totiž v tom, že pokud A i B vzniká každé jiným výpočtem je vysoce pravděpodobné, že se "nikdy nesejdou" a vždy se o "machine epsilon" budou lišit. Pokud tedy jste vůl a píšete A=B kompilátor porovnává tato čísla celočíselnou instrukcí CMP, která je považuje za stejná jedině pokud jsou všechny bity stejné. Správně a bezpečně je tedy IF abs ( A - B ) < Small_number THEN.
Otázka pak je co to má být Small_number - rozhodně to NESMÍ BÝT machine epsilon. Machine epsilon je relativní chyba - nikoliv abslutní hodnota !! Small_number tedy musí být nějaká hodnota, která je "pod rozličovací schopností daného algoritmu". Z toho pak vyplývá, že v extrémně nepříznivém případě musíme mít extra hodnotu typu Small_number pro každé porovnání.
Z tohoto pohledu vypadá porovnání A > B zdánlivě v pohodě, ale opět - za určitých okokností není - představte si, že hodnota A plynule klesá a hodnota B plynule roste - v tom případě, výraz bude dlouho Pravda a pak najednou přeskočí na Nepravda jo ? Může to tak být, ale taky to může být tak, že kolem hodnoty kdy A ( skoro ) = B, díky zaokroulování vyhodnocení podmínky "zakolísá" a bude dávat hodnoty pravda, nepravda, pravda nepravda a pak třeba už bude pokračovat dále jako nepravda.
Že to je "
ezoterický problém", který v praxi nenastává ? Váš robot ale určuje svou trasu pomocí vyhodnocování, jestli je moc vpravo, nebo moc vlevo a cíl pozná podle
POLOHA=CÍL ne ? Počítá s těmito zákeřnostmi váš algoritmus ? Když směr dalšího pohybu určují výrazy A > B nebo A < B - popisuje účinek "
nestabilit" numerických algoritmů starý programátorský vtip : "V
stupujete li do počítačem řízeného výtahu - zapněte si bezpečnostní pás".....

Nakonec se dostáváme k "
politicko-matematické" vložce. Západní společnosti se stále zlepšují - takže na obrázku máte "
bilión" neboli 10
12 dolarů ve stodolarovkách, což je 1/10 ceny za Americká "
válečná dobrodružství" na blízkém východě po
11. září 2001. Pro srovnání - šipka ukazuje lidskou postavu namalovanou vedle "
letiště plného palet se stodolarovkami" - pro srovnání velikosti. Počítání s takovými sumami je nepraktické i pro doporučená "
celá čísla", proto si Američani pro spočtení svých dluhů vymysleli vlastní systém "
plovoucích čísel" zvaných
DECIMAL32 což je analogie "
single" a
DECIMAL64 což je analogie "
double"
Kouzlo je v tom, že to je otrocký převod "vědecké notace" z displeje kalkulačky do PC tedy DECIMAL 32 má 1 bit znaménka 7 čísel mantisy od 0000000 do 9999999 a exponent. DECIMAL 64 je téměř stejný - jen má 16 cifer mantisy, - výhoda je, že miliardy a bilióny v této číselné soustavě se zaokroulují stejně jakoby je "intuitivně" zaokroulil člověk a navíc patrně tyto megasumy nevypadají tak děsivě.
TAkže tolik k reálným číslům - máte li "matematický koprocesor" nebo CUDA grafickou kartu ve vašem robotu - hrr na ně, ale nezapomeňte - opatrnost je na místě.
Mimochodem když vidím ty astronomické peníze a astronomické dluhy - napadá mě jediné čísla ještě "plavou", ale státy se už "potápějí" ?!
Poznámka při druhém čtení - jako obvykle mě ráno na míse napadlo ještě jedno řešení, jak "vydrbat ze systémem". Výraz IF A=B THEN by se možná dal přepsat jako IF A/B = 1 THEN - není vyloučeno, že tam by problémy s "machine epsilon" byly menší, ale zase by tam mohly být problémy se situací kdy A a zejména B by byly zanedbatelně malé až nulové. Jelikož jsem o takové variantě ani nic nečetl - nechávám prošlapávání "Cimrmanovských slepých uliček" tentokrát na čtenářích.
24. prosince 2015 v 5:21 | Petr
Na začátku článku musím probrat otázky "nad dopisy diváků" . Především tedy omluva, za to, že minulý týden jsem místo "robotické matematiky" nabádal ke koupi hvězdářského dalekohledu, ale koukání na hvězdičky s děckama a rodinou je tak příjemné, že jsem to musel napsat ještě před Vánocemi. Druhá otázka je - proč používám pojem "reálné číslo" když v angličtině se to řekne "floating point number". Princip je v tom, že otrockým překladem "real number" vznikne "reálné číslo". Naopak "floating point number" jsem v jednom textu viděl přeložené jako "počet plovoucích teček" a od té doby se tohoto výrazu bojím....
OK dostáváme se k meritu věci - představte si program, který edituje obrázky - vstupem jsou pixely nějakého JPEGu nabývající celočíselných hodnot 0-255 výstupem jsou pixely jiného JPEGu nabývající celočíselných hodnot 0-255 - a způsob jak se s nimi pracuje ? Obrovské pole reálných číslel. Tedy skutečně je to tak - i softwary, které se zdají pracovat s výlučně celočíselnými daty většinou vnitřně pracují s reálnými čísly: první důvod jsme probrali minule - dneska jsou počítače přecpané hardwarovou podporou pro "floating point numbers". Druhý důvod souvisí s tím, že pokud jedno celé číslo přepočítáváte celočíselnou tedy "fixed point" matematikou na jiné číslo - musíte velice pečlivě dbát na to kolik bitů vám kde může přetéct, jak zaokrouhovat, abyste neztráceli přesnost a další zákeřnosti, které jsem zde na blogu ani nezmínil, ale jako programátor v celočíselném assembleru jsem si jich mnoho užil.
Tedy stručně - pokud máme 32 bitovbé celé číslo - buď jej procesor bere jako UNSIGNED - bez znaménka a v tom případě se jedná o celčíselný rozsah 0 - 4294967296. Pokud procesor bere takové číslo jako SIGNED ( se znaménkem ) pak je celočíselný rozsah od -2147483648 do +2147483647. V principu bych se měl stydět, protože procesoru je až na výjimky jedno jestli číslo je SIGNED nebo UNSIGNED - tohle je záležitzost interpretace 32 bitů softwarem. OK - "rozlišovací schopnost" 32 bitového celého čísla je 1 bit - tedy prosté číslo 1 a tato rozlišovací schopnost se hrubě mění podle velikosti čísla - tedy u hodnot 0-1-2- atd činí "Chyba o jedničku" - obrovskou sumu v desítkách procent. Už u 16 bitů není "chyba o jedničku nijak hrozná" rozdíl mezi 65535 a 65536 jsou tři tisíciny procenta - chyba celočíselného výpočtu je tedy "absolutní" a s velikostí čísel postupně klesá.
Jak je to s 32 bity "reálného čísla". V C se 32 bitovému reálnému číslu myslím říká "single" zatímco 64 bitové reálné číslo je "double" podle "single / double precision floating number". Abychom se v reálnch číslech vyznali - je třeba probrat "jak je to uděláno". Tedy "reálná čísla" v počítači jsou de facto stejná jako "dekadická čísla" běžného typu ve "vědecké notaci".
Příklad : Náboj elektronu je -1.6021766208×10−19 Coulombů tedy zápis je Z * M * 10E. kde Z je "znaménko" tedy + nebo - - v binárním tvaru je to 1 bit pak je M - Mantisa která je u "single" čísla 23 bitů - zásadou je že mantisa je vždy "vykrácena", tak aby její hodnota byla 0-1. V binárním tvaru je mantisa vykrácena tak aby nejvyšší bit byl vždy 1 a ten se "zahazuje" a tudíž 23 bitů mantisy umožní uložit 24 bitů. Jedinou výjimkou z tohoto pravidla je číslo 0 slovy "nula" - ta se ukládá tak, že všechny bity mantisy jsou nulové.
Poslední je E - exponent tedy na kolikátou musíme umocnit 10, abychom dostali správný řád čísla. I tohle je u binárních čísel odlišné - tam je exponent na kolikátou musíme umocnit "základ 2" abychom dostali správný řád a u typu "single" je tomu věnováno 8 bitů, které počítače považují za "signed" číslo tedy i Exponent má de-facto znaménkový bit, aby bylo jasné zda číslo je nepatrný zlomek, nebo veliká hodnota.
Pozoruhodné jsou další detaily "jak je to uděláno". Amatér by totiž jednotlivé bity uspořádal "naivně" to jest Zbit pak M bity mantisy pak E bity exponentu. ve skutečnosti je to v počítači úplně jinak první je Z bit, pak jsou E bity exponentu a pak teprve jsou M bity mantisy - tuší někdo ze čtenářstva proč ?

Ano je to tak - instrukce CMP pro porovnání dvou čísel je de-facto jejich rozdíl a procesor čísla odečte výsledek zahodí a pamatuje si akorát "znaménkové bity" tedy kladný, záporný, nebo nula což stačí k rozhodnuté větší, menší nebo stejný. Reálná čísla jsou udělána tak aby ač "reálná" dala se porovnávat stejnou "celočíselnou" instrukcí CMP. Posuďte sami : první je znaménko, protože pochopitelně jakékoliv kladné číslo je větší než jakékoliv záporné. Pak jsou bity exponentu. Tedy pokud znaménkový bit je stejný - a víme že mantisa je 0-1 pak je jasné, že 10 < 11 a tudíž bude 210 < 211. Poslední je pochopitelně mantisa, která se v tomto případě chová jako "svého druhu celé číslo" - takže pokud od sebe odečtete dvě "reálná čísla" celočíselnou instrukcí - vznikne nesmysl, ale znaménko tohoto nesmyslu - kladné, záporné, nulové - je správné.
OK - je tedy na čase zabývat se přesností "single" reálného čísla - základ je v mantise, která má 24 bitů a jak víme tak je vždy ( až na číslo 0 ) zaokrouhlená tak aby první bit ( který se zahazuje ) byl číslo 1 takže "nejmenší rozlišovací schopnost" mantisy je poměr mezi ( binárními ) čísly :
0b10000000 00000000 00000000 a 0b10000000 00000000 00000001 - což je poměr mezi čísly 16 777 216 / 16 777 217 - tedy díky neustálému zaokrouhlování mantisy na "
první platný jedničkový bit" a s tím souvisejícím upravováním velikosti exponentu je "
chyba" neboli "
rozlišovací schopnost" reálných čísel typu "
Single" asi 6*10
-8. Pokud nechceme rozlišovaci schopnost počítat takto vidlácky a složitě - v teorii počítání s reálnými čísly existuje pojem "
machine epsilon" - což je totéž, co naše chyba a ta je pro přesnost "
single" definována jako 2
-24 což je 5.96*10
-8 BINGO
To bychom ale nebyli mezi matematiky, aby to bylo takto vidlácky jednoduché - takže ne všichni jsou toho názoru, že "machine epsilon" neboli teoretická chyba zaokrouhlování se má počítat takto - mezi teoretickými matematiky a informatiky jsou optimisiti, kteří tvrdí že chyba není větší než 2-24 ale pak jsou mezi nimi i pesimisti, kteří tvrdí že chyba může být "o bit větší" a dosáhnout až 2-23 neboli 1.19*10-07.
Jen pro zajímavost typu "Double" - neboli 64 bitů má 1 bit znaménka, 53 bitů mantisy a 11 bitů exponentu - takže tam je "rozlišovací schopnost" neboli "machine epsilon" 2-53 alias 1.11*10-16 pro optimisty a 2-52 neboli 2.22*10-16.
Pro případ veliké diskuse musím na plnou hubu zmínit že "machine epsilon" není "absolutní chyba" - takže ne aby se někdo ptal jak můžeme hodnoty 10-30 počítat s chybou 10-6. Na rozdíl od celých čísel je to relativní chyba takže zaokrouhlovací chyba výpočtu na hladině 10-30 je 10-30 * 10-6 neboli 10-36 jasné ?
OK takže máme tu ty reálnými čísly počítané JPEGy - ale krom toho máme v počítačových hrách v poslední době "
High Dynamic range rendering" a taky ve fotografii máme "
High dynamic range imaging" - takže pozice celých čísel obrázcích se trochu otřásá v základech, ale aby to nebylo tak, že RGB pixel zabere 12 bajtů - rozmáhá se v poslední době formát "
half" - tedy 16 bitová reálná čísla.
Vůbec počítačové reprezentaci reálných čísel která mají méně než 16 bitů se říká "
minifloats" a musím konstatovat, že - jako obvykle -
na Wikipedii je o nich článek, který stojí za přečtení neb dává jasnější představu jak vlastně "
nepřesnost" tohoto číselného formátu vypadá.
10. prosince 2015 v 6:00 | Petr
Bylo nebylo - býval jsem kdysi velmi zadobře s jistým významným pražským biochemickým profesorem - nejednu přednášku jsme spolu udělali, ale pak se on vydal k "
temné straně síly" a mně nezbylo než prohlásit notoricky známé - "
aktivní blb je horší než třídní nepřítel" a dokonce "
pekelná brána se mu už zjevuje" - což jsem dokonce
napsal na tomto blogu. Jaké pak bylo překvapení, když jsem se v jeho poslední knize - dočetl :
Zaostalci mohou být nebezpeční nejen pacientům, ale mohou ohrožovat i seriozní "názorové vůdce", rozvojem pocitu zmaru a beznaděje, při nepřetržitém přesvědčování o kvalitě důkazů, moderních podložených postupů a guidelines ....
A víte o čem ta kniha byla ? O matematice v medicíně, protože oba se považujeme za matematicky orientované - jenom on je vědec a píše články ve stylu "
Implikace Bayesova teorému v interpretaci laboratorních vyšetření" - zatímco já píšu "
Vzácné choroby nelze potvrdit, pouze vyloučit" - asi si myslíte, že jsem vidlák z Frydku a tak mi to patří, ale pozoruhodné je, že obě ty věty - znamenají to samé, co už jsem taky na svém blogu
jednou popsal a to ZDE. Schválně teď udělejte 5 minut pauzu a přečtete si to jestli tomu rozumíte, nebo ne - rozumíte že - takže už víte proč jsem ošoupaný borec s posledními botami.
Proč jsem tu kolegovu "podivnou" knihu četl - prototože jsem hledal inspraci, kterou jsem nakonec nenašel - na přednášku, která by kolegům doktorům vysvětlila něco matematiky, ale aby tam slovo "matematika" nebo "statistika" nebo "implikace" nebo nedej bože "teorém" ani jednou nepadlo, což se mi nakonec povedlo, jenomže když jsem potom byl plný písmen "sigma" a "chí" - tak jsem si uvědomil, že jsem se velice podrobně zabýval celočíselnou matematikou programovanou v assembleru, ale zcela jsem ignoroval "reálná čísla" alias "floating point numbers" a jejich "implikace" pro programování robotů.
Tedy dosti již planého kecání - Použití nebo nepoužití reálných čísel v robotech má minimálně 3 aspekty, které postupně probereme a to :
- Rychlost výpočtu
- Přesnost výpočtu
- Kdy ano a kdy ne - neboli "Zákeřnost"
Dnes tedy máme na programu probrat ještě rychlost. Když si všimnete, tak výkony "superpočítačů" se měří ve FLOPS alias Floating Point Operation Per Second - neboli kolik operací s reálnými čísly daný počítač udělá - vůbec se neberou MIPS - tedy Milióny Instrukcí Per/za Sekudnu. To má své hlubší příčiny.
Příklad - průměr dvou čísel v celočíselné matematice spočtete jako
C = ( A + B ) >> 1
To jsou dvě operace - součet a bitový posun - pak tu ale máme ten problém, že takhle může dojít ke ztrátě přesnosti a musíme průměr zaokrouhlit Tedy :
C = ( A + B + 1 ) >> 1
to už jsou tři operace - tedy o jednu více než když to počítáte "klasicky" s reálnými čísly neboli
C = ( A + B ) / 2
OK - pořád můžete namítat, že Integerových - alias "celočíselných" jednotek je v moderních procesorech více než "floating point" a že celočíselný výpočet půjde rychleji, ale pak si představte "zaokrouhlený" průměr z 5 čísel, který by se ve "float" matematice zapsal takto :
F = ( A + B + C + D + E ) / 5
Jak taky jinak, ale v "integerové" matematice bychom museli napsat :
F = ( A + B + C + D + E + 2.5 ) DIV 5
Zapsat celočíselně 2.5 je problém - takže můžeme rezignovat na přesnost zaokrouhlení a dát tam 2 nebo 3 , nebo napsat něco jako:
F = [ ( A + B + C + D + E ) << 1 + 5 ] DIV 10
To je první problém - druhý problém je jasný - každá "floating point" architektura má instrukci "fdiv" pro dělení, ale "celočíselné dělení "DIV" mají jenom některé procesory a dělit postupně odčítáním a bitovými posuny je hrůza.
Je tedy jasné, že pokud nebereme, pár speciálních výpočtů kde celočiselná matematika v assembleru je rychlejší - pokud má daný procesor matematický koprocesor - neboli Hardwarovou jednotku pro reálná čísla - je výhodnější používat reálná číla - na co to jenom jde ( a na co to nejde probereme v posledním díle ).
Navíc - celéočíselné operace se považují za "
vyřešenou věc" a patrně memůžeme ani u nových procesorů čekat nic převratného, zatímco "
floating point" operace - díky počítačovým hrám a vůbec 3D grafice zažívají obrovský boom - jednak tady existují uvnitř našich počítačů opravdové superpočítače - akorát se jim nějakým omylem říká "
grafické karty" a navíc ani samotné procesory nechtějí zůstat pozadu takže kažého půl roku Intel a ti další oznamují "
nové instrukční sady" - pro reálná čísla - většinou typu SIMD tedy "
single instruction multiple data" - jen pro představu o čem se mluví tak se tomu říká
MMX, SSE1, SSE2, SSE3, SSE4 a tak dále a tak podobně - takže pro reálná čísla zkompilovaný program - rekompilovaný novým kompilátorem, pro nový procesor může velice překvapit, aniž byste v kódu přepisovali jedinou řádku.
Patrně budete namítat, že CORE i7 se vám do SUMO-Robota nevejde, ale o tom se dneska nebavíme - dnes probíráme "
velké roboty" ve stylu
Darpa Robot challenge - a tam se už nějaký "
ATOM", které všechny, bez výjimky jsou těmito "
floating point blbostmi" vybaveny - v pohodě vejde.
OK těšte se na příští týden - kde budeme probírat přesnost / nepřesnost reálných čísel.
25. května 2014 v 5:30 | Petr
Myslím, že po minulých příspěvcích vás souvislosti všeho se vším už tolik neděsí, takže dnes pokračujeme v tom, co vám budou tlouct do hlavy na medicíně a pak to použijete v robotech. Představte si vyšetření sluchu, které se dělá tak, že v tiché místnosti sedíte se sluchátky na uších, do sluchátek vám píská sinusovka na různých frekvencích a různou intenzitou a vy mačkáte tlačítko SLYŠÍM / NESLYŠÍM. Podle toho se pak určí tzv Audiogram - to jest křivka citlivosti vašeho ucha v závislosti na frekvenci.
Pak si představte drobný zádrhel - třeba, že jste tak trochu simulant, který chce na zaměstnavateli odškodné za "poškození sluchu". Nebo jste dítě - zcela ve svém světě a nespolupracující - a nikdo neví jestli je to kvůli hluchotě, nebo je to mentální postižení. Po lidech tohoto typu nikdo nemůže chtít, aby mačkali tlačítko - tak jak zjistit, jestli slyší, nebo neslyší ??
Představte si, že takovému člověku nasadíte na hlavu čapku s desítkami elektrod pro snímání EEG. tedy Elektro - Encefalo - Gramu - tedy elektrické aktivity mozku. Kromě toho mu nasadíte sluchátka a do těch mu pouštíte pravidelné kratičké "cvakání". Co bude na EEG - 99% signálu bude tvořit aktivita mozku, která se sluchem vůbec nesouvisí a 1% bude aktivita sluchové mozkové kůry. Tím že těch cvaknutí bude kolem 10 000 můžete záznam po každém cvaknutí průměrovat.
Tím se vám těch 99% které nejsou synchronní s cvakáním vzájemně posčítá a poodečítá a nakonec vám ze záznamu vyplyne to, co je s cvakáním synchronní a to je aktivita sluchové mozkové kůry. Jak taková aktivita má vypadat - víme od zdravých, kteří nám nelžou o svém sluchu - jestli u pacienta vypadá tato aktivita stejně - bingo - máme tě lumpe, protože říkat můžeš, co chceš, ale neurony v mozku jsou na lhaní příliš hloupoučké. Samozřejmě existuje celá knihovna různých patologických záznamů - takže pokud člověk skutěčně neslyší - můžeme odhadnout relativně přesně proč.
To samé se dělá i se zrakem, kde je to ještě zajímavější - za léta vyšetřování se totiž ustálil protokol kdy vyšetřovaný kouká na obrazovku PC, kde má černo-bílou šachovnici. Stimulační podnět je to že si bílé a černé čtverečky - vymění místa - což je z hlediska EEG silnější podnět, než pornokazeta s blondýnami.
Opět zbývá nepatrná maličkost - co má tohle společného s roboty a jejich senzory ? Už kdysi jsme probírali
LOCK IN zesilovače, kde jsme pomocí externího synchronizačního signálu nabíjeli střídavě referenční a měřící kondenzátor. Pak jsme opakovaně probírali
spínané mixéry, které kupodivu jsou totéž co
lock in zesilovače.
Výše uvedená řešení jsou čistě analogová - není ovšem problém si představit procesor digitalizující signál, který při digitalizaci místo nabíjení kondenzátorů počítá průměry - když signál je a když signál není přítomen. Pak si samozřejmě nění problém představit, že procesor ukládá digitalizované výsledky do více než jedné proměnné. A to je přesně totéž co doktoři používají při evokovaných potenciálech.
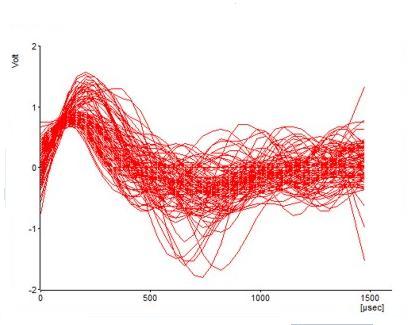
Příklad z praxe - u
BackEMF můstků máte ten problém, že DC motor produkuje napětí, které kolísá podle toho jak je zrovna natočen komutátor. Pokud máte spínací frekvenci PWM 1000 HZ ale frekvenci řízení PID regulace jen 50 Hz - není problém měřit napětí na motoru při každém cyklu a průměrovat. A protože tam je "
spajk" překmitu proudu - je lepší nečekat na jeho konec ale prostě měřit naslepo více hodnot, které v malém bufferu průměrujeme při každém cyku a teprve při spuštění PID regulace, kdy je daleko více času - rozhodnout která hodnota v bufferu je "
překmit" a která je napětí generované volně rotujícím motorem.
Doufám, že z toho nejste příliš velcí jeleni - zkráceně vzato - představte si že máte nějaký synchronizační signál a od tohoto signálu digitalizujeme 100 hodnot, které opakovaně průměrujeme klouzavým průměrem se 100 hodnotami co máme v bufferu z předchozích měření. V průměrech pak pátráme po tom, co je se signálem opravdu synchronní, protože to ostatní - nesynchronní - se nám po jisté době měření zprůměruje do rovné přímky. Jasné ?
Zbývá už jenom oblíbená rada pro brunety - máte v noci divoké sny, že vás miláček násilní v zakladačovém skladu IKEA ? Je jaro - šup na to - nic jiného než "podmínka" za veřejné pobuřování vám nehrozí a ještě proniknete na obrazovku TV Nova.
8. května 2014 v 5:46 | Petr
Minule jsem zase pustil šílenství na špacír a probíral kde všude matička příroda (a programátoři) používají "Unsharp Mask". A nakonec jsme skončili u toho že laterální inhibice - to jest když silně osvětlená buňka sítnice blokuje své sousedky - není z matematického hlediska zase taková sranda.
Nyní tedy jsme ve stavu kdy máme buffer s daty, kde potřebujeme zaostřit (nebo vyhledat) hrany a pak si do druhého bufferu připravíme masku kterou od původních dat odečteme aby nám "hrany vystoupily".
Naivní přístup jak připravit neostrou masku je průměrování sousedních hodnot. Jak vidíte z grafu - tak maska se svými monotónně stoupajícími a klesajícími hranami není nic moc - a asi by se nám v Photoshopu takto zaostřený obrázek nelíbil. Proto se jako zdroj masky používá Gaussovský rozptyl. I my vidláci si můžeme zpracovat gaussovskou masku, pokud počítáme pomocí váženého průměru podle vzorečku
Y (n) = A1 * X(n-3) + A2 * X(n-2) + A3 * X(n-1) + A4 * X(n) + A5 * X(n+1) + A6 * X(n+2) + A7 * X(n+3)
Kde A1-A7 jsou koeficienty tvaru gaussovy křivky jsou to členy tzv.
Pascalových trojúhelníků. Konkrétně v našem případě tedy vzoreček bude :
Y (n) = ( X(n-3) + 6 * X(n-2) + 15 * X(n-1) + 20 * X(n) + 15 * X(n+1) + 6 * X(n+2) + X(n+3) ) / 64
Jistě jste pochopili že tuto metodu generování masky nezvládne ani má milovaná nadupaná ATMega8 na 16 MHz. Proto je třeba na věc jít švindlem.
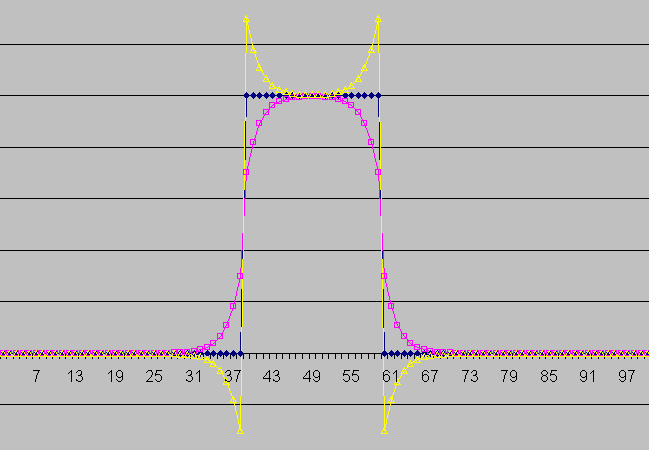
Co je to Gaussova křivka - bratři anglosassové říkají "
bell curve" - zvonovitá křivka (ne oblíbená lehká děva
A. G. Bella !!). tak si ke zvonovité masce dopomůžeme fintou. Jak vidíte na obrázku nahoře máme krásnou plynulou masku a taky zaostřování hran funguje, že by se ani Photoshop nemusel stydět.
Zbývá jenom otázka jakou nečestnou finotu jsme si pomohli ? Exponenciálním klouzavým průměrem, který má ale tu nevýhodu, že neprodukuje tak pěkně symetrické masky, tak jsem musel udělat nečestnou fintu na druhou - to jest spočítat dva exponenciální průměry - jeden "ve směru času" a druhý "proti směru času" a sečíst je dohromady. Podrobným průzkumem obrázku nahoře zjistíte, že je to skutečně tak.
Matematici sice křičí, že to není pravá Gaussova křivka, ale lepší aproximaci za cenu tak nepatrného výpočetního výkonu se mi prostě nepodařilo objevit - čímž dávám příležitost diskutujícím.
Další věc, na které moje milované AVR už nestačí - je totéž ale ve 2 rozměrech - jak bych postupoval tam - netuším - možná bych dělal dva průměry ve směru řádků a dva ve směru sloupců ? Nebo bych vymyslel něco na principu
error diffusion při vykreslování obrázků ? Nevím, ale doufám, že insiprování tímto článečkem vám to nebude činit problémy.Což mě přivádí k myšlence, že výroba gaussovských neostrých masek asi nebude taková sranda, když to výrobci grafických karet kdysi inzerovali jako výhodu
CUDA - tedy počítání matematiky na grafické kartě.
Dalších pár počítacích fintiček jsme probrali - zbývá už jenom tradiční rada pro brunety - Chcete dohnat ženskou mrchovitost a mužský stres do krajnosti ? Nechte těhotné kamárádce počůrat těhotenský test a ukažte jej miláčkovi jako svůj vlastní - možná teprve potom pochopíte co je to
Richterova škála u zemětřesení.
1. května 2014 v 5:54 | Petr
Musím přiznat, že se sepsáním tohoto článečku jsem velice váhal, protože nemohu zakrýt jistý fakt z mé oblíbené patologické oblasti známé pod heslem "
vše spolu tak nějak souvisí". Takže nevím jestli tento článeček patří do "
matematiky", nebo jestli by se stejně tak nemohl uplatnit v "
neurovědách".
Laterální inhibice z nadpisu je totiž něco, co jsem se naučil ve fyzilogii na medicíně, a pak to léta úspěšně používal v robotech. Laterální inhibice - otrocky přeloženo "blokáda do boku" je totiž fenomén z říše zvířat. Silně osvětlená buňka sítnice totiž částečně blokuje své slaběji osvětlené sousedky. To je proto aby se nám silný signál "nerozpliznul" do okolí a obraz tak neztratil svoji ostrost.
Zde je optická iluze zvaná Hermanova mřížka, která to pěkně ilustruje. Divák se nemůže zbavit dojmu že průsečíky bílých úseček jsou tmavší než oblasti mezi černými čtverečky. To je právě proto že na "křižovatce" se vám střetávají 4 bílé úsečky - tudíž bílého jasu je tam mnohem více a tudíž "laterální inhibice" kterou vidíme na bílé - nikoliv na černé - je tam nejsilnější.
Zcela stejný proces probíhá i v klasické "
analogové fotografii" - když vyvoláváte fotky - máte fotkou v misce pohybovat aby se vám dostaly k emulzi čisté chemikálie, pokud právě naopak vezmete gumový váleček a fotku po prvním namočení do vývojky "
naválcujete" na sklo dojde k tomu, že na rozhraní černá / bílá dojde k nerovnoměrnému vyčerpání vývojky a to tak že na černých oblastech se vývojka více vyčerá a proto jsou sousední bílé oblasti "
ještě bělejší". Celé se to jmenuje
Sabatierův efekt a v době před Phostoshopem to byla oblíbená metoda "
analogového zaostřování".
Když už jsme u toho Photoshopu - ač si puboši myslí opak - Photoshop jen kopíruje možnosti mokré chemie. Snad krom toho, že nyní mohou "laterální inhibici" využívat i líní a nešikovní, kteří by kdysi byli akorát pobryndaní od vývojky. V Photoshopu se tato funkce jmenuje "unsharp mask" - otrocky přeloženo "rozostřená maska", která využívá přesně stejných matematických principů jako matička příroda a staří fotografové.
Aby šílenství bylo dokonalé - zcela stejný princip - difuze čerstvé kyseliny nás otravuje při "podleptávání" cestiček na plošných spojích - na hranici odleptané / neodleptané mědi totiž probíhá leptání daleko rychleji nez na velkých plochách - díky přílivu čerstvé kyseliny z oblastí už bez mědi....
Takže pokud potřebujemem nějaký signál "zaostřit" nebo v něm hledáme hrany klidně k tomu můžeme přistoupit naivně a udělat si učebnicový příklad laterální inhibice. Prostě počítáme výstup podle následujícího vzorečku :
Y(n)= 2 * X(n) - X(n-1) - X(n+1)
Tento postup je jednoduchoučký, rychlý ( v assembleru místo násobení použijeme bitový posun) a nepotřebuje žádnou paměť navíc krom vstupního a výstupního bufferu.
Výsledkem však je, že vám zcela zmizí "stejnosměrná úroveň signálu". proto je lepší vzoreček naprogramovat jako
Y(n)= A * X(n) - B*( X(n-1) + X(n+1) )
Kde A a B jsou koeficienty, se kterými si můžete hrát. Takže pokud potřebujete zachovat stejnosměrnou úroveň musí být A = 2*B+1. Například zde máme graf pro A= 3 a B = 1
Když rozebereme vzoreček podrobněji tak vidíme že X(n-1) + X(n+1) je vlastně maska, která je rozostřená součtem sousedících hodnot. Tento postup je jednoduchoučký, ale pokud jste pravidelnými čtenáři "matematiky" je vám jistě jasné, že takto jednoduše to s reálnými daty jde jenom občas.
Problémy jsou v zásadě dva :
- Musíte znát hodnoty dat "z budoucnosti" - což reprezentuje člen X(N+1), ale řekněme, že toto jde překonat, když držíme data v malinkatém bufferu
- Pokud se chceme zbavit šumu v datech musíme vstupní data prohnat nějakou numerickou dolní propustí - tedy buď lineárním, nebo exponenciálním klouzavým průměrem. Pokud klouzavý průměr průměruje třeba 5 sousedních hodnot - maska, aby byla účinná musí průměrovat ještě o něco více, proto hrozí, že zde uvedeným jednoduchoučkým způsobem budeme některá data sčítat zbytečně stále znova a znova dokola.
Z toho důvodu od jisté složitosti "laterální inhibice" stojí za to připravit si masku předem do druhého bufferu a pak masku a data prostě odečíst. Jak na to budeme řešit příště, neb řada čtenárů včetně mně jsou jeleni už teď.
Zbývá nám už jenom tradiční rada pro brunety - bruneta, která je dost chytrá na to aby nechodila s nosem nahoru a dokonce se umí tvářit jako "skromný Bobík" - je prostě ještě více sexy než kdejaká blondýna s umělýma pazourama, vlasama, ověšená drahou kabelkou a dalšímí "cingrlaty".
5. prosince 2013 v 5:57 | Petr
Už kdysi dávno jsem psal o "
robotické blbuvzdornosti" tedy o tom, že i do malinkatých robotů je dobré vestavět jisté ochranné prvky, zejména tehdy pokud to nestojí moc práce ani peněz.
Jednou ze součástí takové blbuvzdornosti je spolehlivost posílání dat mezi moduly v robotech. Takže teď odbočím a zopakuju starou větu :
KATEGORICKY ZAKAZUJU POUŽÍVAT I2C SBĚRNICI PRO DŮLEŽITÁ DATA. Kdysi jsem doporučoval používat diferenciální sběrnice RS485, CanBus, Robbus, USB, Ethernet atd. Vtip je v tom, že pokud máme i přes použitou sběrnici jsté množství chyb v doručených datech - je čas začít uvažova zda místo surových dat poslaných po sběrnici není čas používat "
samoopravné kódy".
Takže přestavte si, že posíláme data poruchovým kanálem - máme celkem 3 možnosti
- vůbec nekontrolujeme správnost - přijmeme vadný paket - robot podle něj jede - škubne a něco rozbije ...
- V datovém paketu máme nějakou kontrolu - paritní bit, kontrolní součet atd.... Takže přijmeme paket - vyloučíme jej jako vadný a čekáme na další, který může být taky vadný, další taky a další ...
- Už při připravě dat pro paket před vysíláním - přidáme "něco navíc" data, která umožní poznat a dokonce i obnovit původní informaci. Pak přijmeme vadný paket, obnovíme jeho data a jedeme dále jakoby se nic nedělo.
Patrně je vám jasné, že samoopravné kódy jsou to nejběžnější kolem nás. Vtip je v tom, že tolik věcí jsme dotlačili až na fyzíkální limity - jako datové toky ve WIFI, kapacitu pevných a flash disků, kapacitu CD/DVD, že chyby v datech na těcho médiích jsou zcela běžné - "ale zákazník to nesmí poznat...."
Takže jsem se kdysi rozhodl, že ovládnu alespoň nějakou formu samoopravného kódovaní, a protože jsem matematický nedouk, tak jsem ovládl jenom tu historicky první a nejjednodušší metodu - což jsou tzv.
Hammingovy kódy.
Richard Hamming v roce 1950 zavedl způsob jak výrazně zvýšit spolehlivost děrných štítků a to tím, že ke každým 4 bitům dat přidal 3 bity parity. Jeho 7 bitový kód pak vypadá následovně
Tedy první dva bity jsou parita, pak je jeden datový bit, pak je poslední paritní bit a další tři datové bity.
Malá odbočka k pojmu PARITA. Tedy od pradávných digitálních dob se nejzákladnější kontrola dat dělala tak že k určitému počtu datových bitů se přidal bit navíc - paritní - a jeho hodnota se nastavila tak, aby datový paket měl vždy SUDÝ nebo vždy LICHÝ počet "jedničkových" bitů (proto sudá nebo lichá parita). Pokud tomu tak nebylo bylo jasné, že některý bit se přenosem změnil. Pokud se prohodily vzájemně dva bity - parita zase seděla ačkoliv data byla špatná - ale pravděpodobnost dvou chyb v jednom paketu (bajtu) se považovala za velmi nepravděpodonou.
Paritní bit se spočte prostě tak že uděláte XOR všech datových bitů - výsledek dává SUDOU paritu, pokud výsedek NEGujete dostanete LICHOU paritu.
| / | P1 | P2 | D1 | P3 | D2 | D3 | D4 |
| P1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| P2 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| P3 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
Takže Hammingovy kódy mají 3 paritní bity, které každý počítají paritu z jiné části datového slova ze kterých bitů se počítá který paritní bit máte označeno v tabulce označeno. Tedy pokud XORem budeme počítat jednotlivé paritní bity potom platí
P1 = D1 xor D2 xor D4
P2 = D1 xor D2 xor D3
P3 = D2 xor D3 xor D4
Tak tohle už smrdí maximální černou magií - takže je čas vysvětlovat. Paritní a datové bity jsou totiř rozmístěny tak šikovně, že nám umožňují poznat který bit je špatný. Postup je následující:
- Přijmu datový paket a někam si uložím tři paritní bity.
- Potom si spočtu paritní bity z datových
- Pak tři paritní bity z datového paketu XORuju s vypočtenými paritními bity
- Získám 3 bitové číslo které nabývá hodnot 0-7
- na tuto hodnotu se mohu rovnou dívat jako na pozici chyby - tedy 0 - vše správně 3 - chyba je ve 3 bitu (D1) nebo třeba 4 - chyba je v paritním bitu P3
- takže pokud získám číslo různé od nuly prostě jenom mechanicky XORuju bit na patřičné pozici jedničkou a mám správný paket.
Opět drobní ďáblici v detailech - co když dojde k poruše více než jednoho bitu - pak patrně nepoznám, že i po korekci mám špatný paket.
Toho využívají i technici a nepraktické 7 bitové pakety doplní ještě o jeden paritní bit, který počítá paritu všech 8 bitů - to je tzv Hammingův kód 8/4, který se také nazývá "Single error correcting double error detecting" - tedy jednu chybu opravím dvě chyby poznám.
Jak se pracuje s takovým kódem :
- Dekóduju a opravím bity jako v předchozím postupu
- Pak opravené celé slovo zkontroluju jesti i 4 paritní bit sedí
- Pokud sedí mohu data použít
- Pokud nesedí - je zjevné, že datové slovo bylo poškozeno "beyond repair" (za hranice opravitelnosti) a musím jej vyhodit.
Jak to budeme programovat v praxi ? - nemá smysl smolit s v mikrokontroléru s XORováním bitů takže je dobré:
- Rozdělit odesílaný bajt na 2 4 bitové úseky
- Pro každou možnou 4 bitovou hodnotu mít v tabulce už předem předvypočtenou hodnotu hammingova kódu, který se odešle (je jich jenom 16).
- Při příjmu mít v druhé tabulce předem vypočtenou hodnotu všech 265 hodnot, které mohou přijít spolu s hodnotou jaký 4 bitový "nibble" to vlastně je a u těch kombinací které jsou poškozeny "beyond repair" mít hodnotu třeba 16 - abychom věděli, že tento nibble nesmíme použít.
Osobně jsem používal pro výpočet P1-P3 sudou paritu, ale pro P4 lichou paritu - to proto aby "plochá lajna na lince" tedy hodnoty 00000000 a 11111111 dávaly chybu.
Prográmek v assembleru zase neuvádím (protože se za něj stydím). Místo toho jsem
nahrál na ULOŽ.TO excelovskou tabulku, pomocí které jsem si celou věc zkoušel (a vypočetl jsem si pomocí ní obě tabulky do programu). Doporučuju prozkoumat a při trápení se jak to mám udělané - Hammingovy kódy pochopit.
Zbývá už jenom tradiční rada pro brunety : nejsou jenom vysoké kozačky až na stehno - ale jehlové kozačky po kotník a odtamtud černé legíny vedoucí po vašich dlóóóuhých nohách "až k pipně" - taky dovedou chlapem otřást.
28. listopadu 2013 v 5:37 | Petr
Nebudu začínat ultrazvukem, ale představte si, že byste chtěli to nejjednodušší, co si u robotů představuje každé 2 leté děcko - aby robot vydával nějaké "bojové pokřiky"
Takže trošku počítejme - představte si že budete chtít do robota naprogramovat 1 sekundu toho nejubožejšího zvuku. Takže berme, že vzorkovací frekvence bude 8KHz (pro rozsah alespoň do 4 KHz řečového pásma) a hloubka vzorkování bude 8 bitů. To máme 8 kilobyte / sec - při kvalitě zvuku, který se "vyrovná" nejubožejším hračkám od Vietnamce.
Takže vás okamžtě napadne, že je potřebná nějaká datová komprese. Začnete studovat běžné učebnicové algoritmy a zjistíte, že žádný není pro zvuk příliš vhodný. Co je vhodné je varianta FFT = DCT = JPEG = MP3 komprese, ale to je na naše matematické schopnosti i na ubohý výkon našeho procesoru zase příliš.
Takže první věc, která vás napadne - nebudu ukládat celý vzorek, ale jenom rozdíl oproti minulému vzorku - BINGO - vzhledem k tomu, že zvuky jsou většinou hladké sinusovky, bude nejčastější rodíl téměř 0, takže nemusíte ukládat celých 8 bitů rozdílu, protože (třeba) horní 4 bity jsou skoro vždycky 0, ale ukládáte jenom spodní 4 bity. Máte zvuk jenom o něco málo ubožejší než předtím, a přitom polovinu dat. Tak tomuhle se říká DELTA MODULATION.
Delta modulace má dvě drobné chybky
1. Komprese v poměru 1:2 není nic moc
2. U prudkých výkyvů zvuku se často vyskytuje "podtečení delta" - tedy rozdíl vzorků je více než vaše maximální hodnota delta.
Proto můžeme použít "expanzi delta" ve smyslu následující tabulky
| Vyslaný kód | Hodnota delta |
| -3 | -64 |
| -2 | -8 |
| -1 | -1 |
| 0 | 0 |
| 1 | 1 |
| 2 | 8 |
| 3 | 64 |
Takže do databáze si uložíme 3bitové signed hodnoty a delta vybíráme z tabulky.
Postup jak se "surová data" třeba z WAW souboru kódují do podoby delta hodnot se nazývá Error Diffusion. Tedy při výpočtu odeslání "expandovaného delta" vznikne určitá chyba, která se přičte k hodnotě minulého vzorku aby se vzala do úvahy při výpočtu dalšího vzorku a nekumulovala se.
Příklad v Pseudokódu.
TRUE_ DELTA = CURRENT_X - LAST_X
SEND_DELTA = compress_delta (TRUE_DELTA)
ERROR_DELTA = TRUE_DELTA - expand_delta ( SEND_DELTA )
LAST_X = LAST_X + ERROR_DELTA
Jak jste jistě pochopili tak procedura COMPRESS_DELTA vezme skutečnou hodnotu delta a snaží se najít, která hodnota z pravého sloupce tabulky (tedy -64, -8, -1, 0, 1, 8, 64) je hodnotě delta nejbližší a podle toho vrací hodnotu -3 až +3.
Stejně tak je myslím jasné, že procedura EXPAND_DELTA bere hodnoty -3 až +3 a vrací -64, -8, -1, 0, 1, 8, 64.
Jasné ?
Stále máme ubohý zvuk, kompresi 3:8 a algoritmus jako hrom. Aby to bylo ještě horší když začnete studovat jaké hodnoty delta jsou vhodné zjistíte, že kolem toho je literatury jako hrom, protože to je oblíbené téma akadademiků. Nicméně od 70. let existuje metoda, která zajistí kompresi akustického signálu v poměru 1:8 tedy jeden vzorek kóduje se jedním bitem, nic se nemusí nastavovat a algoritmus si delta nastaví sám. Jistě tušíte, že to je to záhadné CVSDM.
Takže ukázka v pseudokódu:
ACCUMULATOR = 0
DELTA = 1
FOR I=0 TO SAMPLE_COUNT
IF SAMPLE > ACCUMULATOR THEN
BEGIN
send (1)
ACCUMULATOR = ACCUMULATOR + DELTA
END
ELSE
BEGIN
send (0)
ACCUMULATOR = ACCUMULATOR - DELTA
END
IF (last_3_send_bits = 0b111) or (last_3_send_bits = 0b000) THEN DELTA = DELTA * 2
ELSE DELTA = ( DELTA +1 ) div 2
ACCUMULATOR = ( 120 * ACCUMULATOR + 64 ) >> 7
NEXT I
Jasné ?
Předpokládám že ne zcela takže se to pokusím ještě popsat slovy. Hodnota ACCUMULATOR - de facto nese součet všech hodnot DELTA, které už byly odeslány. Nový vzorek se porovoná s hodnotou ACCUMULATORU a podle toho se pošle 1 - když je vzorek větší , nebo 0 když je menší a hodnota DELTA se podle toho k akumulátoru přičte / odečte.
Pak následuje záhadná část s úpravami hodnot delta. Pokud poslední 3 vzorky byly všechy menší nebo všechny větší než AKUMULATOR (to znamená že se odeslaly 3 x 1 nebo 3 x 0 za sebou)- znamená to, že hodnota DELTA je příliš malá - proto se zdvojnásobí, pokud nenastala ani jedna z těchno variant hodnota delta se zmenší na polovinu, ale ne na nulu, proto tam je to (DELTA +1) / 2.
Předposlední řádek je naprosto záhadná manipulace s hodnotou AKUMULÁTORU - jedná se o to, že pokud tento algoritmus použijeme pro přenos dat z jednoho místa do jiného a dojde k chybě přenosu - hodnota akumulátoru by se už nikdy nesrovnala - tento algoritmus se nazývá LEAKY ACCUMULATOR (prosakující akumulátor). Tedy hodnota akumulátoru se vlastně exponenciálně půměruje k nule aby se chyba přenosu postupně "vstřebala".
Dekódování je zrcadlovým obrazem kódování včetně leaky accumulatoru. Tedy udržujete hodnotu DELTA a přičítáte / odečítáte ji od hodnoty ACCUMULATORu a hodnota ACCUMULATORU je vlastně výstup celého kódování.
Jak vypadá originální a dekódovaný signál vidíte na obrázku - ty ostré "spajky" v dekódovaném signálu jsou situace kdy hodnota DELTA vzrostla až příliš - pokud vám vadí stačí prohnat výstup tím nejjednodušším exponenciláním průměrem. Zásadní výhoda CVSDM je v tom, že klidně můžete algoritmus beze změny použít i pro 16 bitové hodnoty - pozor na přetečení pracovních proměnných zejména při výpočtu LEAKY ACCUMULATORU. Hodnota DELTA se automaticky přizpůsobí. Navíc komprese 1:8 je dostatečná na to abyste si mohli dovolit samplovací frekvenci 16kHz a to je v signálu slyšet jako výrazné zlepšení zvuku.
Takže nakonec jsme došli k paradoxu ztrátových kompresí - ztrátově komprimovaný signál je někdy lepší než nekomprimovaný - alias na velikém vysoce komprimovaném JPEGu vidíme více než na maličkém GIFu.
Zbývá už jenom tradiční rada pro brunety - nepadnou vám ohnivě červené kozačky, které jsou v obchodě poslední - nic si z toho nedělejte - ve vedlejším regálu jsou černé důchodky a je jich tam spousta....
29. září 2013 v 5:13 | Petr
Klidně si užívám toho, jak jsem na dovolené a moje mladá manželka nehne v domácnosti ani prstem - a najednou se nad minulým dílem "
Matematiky" rozhořela diskuse skoro jakobych se pokusil zabít nějaké zlaté tele. No asi ano, protože v diskusi dokonce padlo odvážné "
zkuste uložit JPEG na SD kartu v Assembleru" - no ukládá snad žirafa, nebo brouk hrobařík JPEG na SD kartu ? A jak jim to funguje ?
Když už tak rýpu, tak si rýpnu ještě - ukládání JPEGů na SD kartu - to je typická "úloha moderní doby" - kdy je snadné zjistit kolik napršelo na Times Square v New Yorku, ale zjistit kolik mi napršelo na zahrádce je "technological challenge".
Takže vše se točí kolem
Saturační aritmetiky a sčítání a odčítání v ní. V diskusi jsem dostal moře dotazů - typu kolik je -1+(-1) atd. Tyto otázky bych rozdělil celkem do 8 variant, které postupně proberu, a abych mé čtenáře nepletl 4, 8 a 16 bitovými čísly tak dneska se pohybujeme striktně v oblasti 8 bitů - tedy
int8_t a
uint8_t
1. Unsigned integer - uint8_t. - čísla se nám pohybují od 0 do 255 tedy 0b00000000 do 0b11111111
A. Je možné aby A+B < 0 - není - protože pro záporná čísla nemáme ani bitové vyjádření navíc nejnepříznivější případ je A+0 = A
B. Je možné aby A+B > 255 - snadno a proto procesor nastavuje Carry bit který je de-facto 9 bit sčítaných registrů. Ergo příklad saturačního sčítání uint8_t už jsem uvedl.
ADD R16, R17
BRCC Continue
LDI R16, 255
:Continue
C. Je možné aby A-B > 255 - pokud jsou A i B v rozsahu - není - pilným nedůvěřivcům doproučuju zkusit všech 65536 kombinací .
D. Je možné aby
A-B < 0 - velmi snadno stačí aby
B > A, ale zde nám začínají
problémy s Carry bitem - protože některé architektury používají při odčítání Carry - pořád jako Carry - tedy 9 bit - tedy při regulérním odčítání typu 5-3 alias 5+(-3) je
Carry nastaven, Zatímco oblíbené AVR a ostatní starší architektury používají
Carry jako Borrow - tedy při operaci typu 5-3 není nastaven, zato je nastaven při operaci typu 3-5. takže berte jako fakt, že pro
saturační odčítání uint8_t v AVR platí
SUB R16, R17
BRCC Continue
CLR R16
:Continue
2. Signed integer - int8_t - tedy čísla se nám pohybují od -128 do +127 to je od 0b10000000 do 0b01111111
A. je možne aby A+B < -128 - ano snadno -100 + (-100) = -200
B. Je možné aby A+B > 127 - ano snadno 100 + 100 = 200
Tím jsme v průseru neboť na rozdíl od Unsigned varianty - nám žádná možnost "automaticky nevypadává".
Tedy je jasné , že pomocí Overflow detekujeme přetečení - když nenastane budeme ve výpočtu pokračovat. Když nastane potřebujeme nějakou možnost, jak zjistit, jestli místo přetečeného výsledku dosazujeme +127 nebo -128.
Minule jsem psal, že Carry si nevšímáme jelikož ale všechny procesory sčítají stejně (unsigned jako signed) a nastavují vždy Overflow i Carry - můžeme toho "kreativně využít".
Nejprve je třeba si položit otázku jestli součtem kladného a záporného čísla se můžeme dostat mimo limit - a odpověď je nikoliv. To nám ohromně pomáhá, protože to znamená, že problémy dělají buď součty dvou kladných, nebo dvou záporných. Kladná čísla v Signed variantě jsou vždy 0B0XXXXXXX - tedy není cesta jak součtem dvou čísel s nulou v osmém bitu nechat výsledek přetéct do devátého (Carry) bitu - a tedy Carry není nastaven když jsme přetekli směrem ke 127, A naopak....
Takže příkládek saturačního sčítání int8_t je zde.
ADD R16, R17 ; Sčítáme
BRVC EndProc ; nepřetekli jsme takže končíme
BRCC PosOverflow ; přetekli jsme na kladnou stranu takže jdeme dosadit 127
LDI R16, -128 ; přetekli jsme na zápornou stranu - dosazujeme -128
RJMP EndProc ; a končíme
:PosOverflow
LDI R16, 127 ; při kladném přetečení dosazujeme 127
:EndProc
C. je možné aby A-B < -128 - Ano -100 - (+100) = -200
D. Je možné aby A-B > 127 Ano 100- (-100) = 200
E. Je možné aby 0-B > 127 Ano 0-(-128) =128
Doufám, že po minulém příkládku vás nebere migréna. Takže postup je jasný, nejprve podle Overflow rozhodneme jestli k něčemu vůbec došlo a pak pomocí Carry rozhodneme zda výsledek nahradíme +127 nebo -128. jedinou věc, kterou je třeba rozmyslet je která hodnota Carry znamená co takže vezměme příklad C.
To je 0b100110 - 0b0110100 - z hlediska carry bitu (unsigned čísel) odečítáme menší číslo od většího a Carry nebude nastaven - takže nebude - li carry nastaven dosazujeme -128.
Vezměme příklad D. 0b0110100 - 0b100110 - carry bit bude nastaven - a my dosazujeme +127, což (naštěstí) zahrnuje i příklad E. Tedy :
SUB R16, R17 ; Odečítáme
BRVC EndProc ; nepřetekli jsme takže končíme
BRCC NegOverflow ; přetekli jsme bez Carry takže jdeme dosadit -128
LDI R16, 127 ; přetekli jsme s Carry takže dosazujeme 127
RJMP EndProc ; a končíme
:NegOverflow
LDI R16, -128 ; dosazujeme -128 a končíme
:EndProc¨
Jasné ?
Všech 8 varinat i mně jsme vyčerpali. Takže jenom několik poznámek :
1. C prý s Overflow bitem vůbec neumí pracovat.
2. x86 architektura harwarově podporuje saturační aritmetiku od doby MMX instrukcí.
3. Skoky v saturačních počtech prý na moderních architekturách dělají úžasný bordel v
Instrukční Pipeline, proto docenti dělají docentury a profesoři profesury na "
Branchless satruration aritmetic" (saturační aritmetika bez větvení) - Schválně si to zadejte do
BINGU a zejnéna na tom jak donutit C přeložit to tak"
jak jsme to zamýšleli"4. Přepsání příkládků z Assembleru do C opět nechávám na C-čkových guruech - já jsem jako žirafa, nebo brouk hrobařík - taky neumím uložit JPEG na SD kartu, a zatím jsem to k ničemu nepotřeboval....
Zbývá už jenom tradiční rada pro brunety : jestli si myslíte, že občas ukázat pipinu a občas ukázat slzičky - stačí k otevření všech dveří - šeredně se mýlíte.